Contrastive Flow Matching
Abstract
Unconditional flow-matching trains diffusion models to transport samples from a source distribution to a target distribution by enforcing that the flows between sample pairs are unique. However, in conditional settings (e.g., class-conditioned models), this uniqueness is no longer guaranteed—flows from different conditions may overlap, leading to more ambiguous generations. We introduce Contrastive Flow Matching, an extension to the flow matching objective that explicitly enforces uniqueness across all conditional flows, enhancing condition separation. Our approach adds a contrastive objective that maximizes dissimilarities between predicted flows from arbitrary sample pairs. We validate Contrastive Flow Matching by conducting extensive experiments across varying model architectures on both class-conditioned (ImageNet-1k) and text-to-image (CC3M) benchmarks. Notably, we find that training models with Contrastive Flow Matching (1) improves training speed by a factor of up to , (2) requires up to fewer de-noising steps and (3) lowers FID by up to compared to training the same models with flow matching. We release our code at: https://github.com/gstoica27/DeltaFM.git.
![[Uncaptioned image]](https://imagedelivery.net/IbyzYGTnLFuE_HViPeiBMw/2506.05350/extracted/6514412/figures/imgs/teaser_figv2.png/public)
1 Introduction
Flow matching for generative modeling trains continuous normalizing flows by regressing ideal probability flow fields between a base (noise) distribution and the data distribution [25]. This approach enables straight-line generative trajectories and has demonstrated competitive image synthesis quality. However, for conditional generation (e.g., class-conditional image generation), vanilla flow matching models often produce outputs that resemble an “average” of the possible images for a given condition, rather than a distinct mode of that condition. In essence, the model may collapse multiple diverse outputs into a single trajectory, yielding samples that lack the expected specificity and diversity for each condition [29, 44]. By contrast, an unconditional flow model—tasked with covering the entire data distribution without any conditioning—implicitly learns more varied flows for different modes of the data. Existing conditional flow matching formulations do not enforce the flows to differ across conditions, which can lead to this averaging effect and suboptimal generation fidelity.

To address these limitations and improve generation quality, recent work has explored enhancements to structure the generator’s representations and also proposed inference-time guidance strategies. For example, one approach is to incorporate a REPresentation Alignment (REPA) objective to structure the representations at an intermediate layer with those from a high-quality pretrained vision encoder [44]. By using feature embeddings from a DINO self-supervised vision transformer [5, 31], the generative model’s hidden states are guided toward semantically meaningful directions. This representational alignment provides an additional learning signal that has been shown to improve both training convergence and final image fidelity, albeit at the cost of requiring an external pretrained encoder and an auxiliary loss term. Another popular technique is classifier-free guidance (CFG) for conditional generation [18], which involves jointly training the model in unconditional and conditional modes (often by randomly dropping the condition during training). At inference time, CFG performs two forward passes—one with the conditioning input and one without—and then extrapolates between the two outputs to push the sample closer to the conditional target [29, 18]. While CFG can significantly enhance image detail and adherence to the prompt or class label, it doubles the sampling cost and complicates training by necessitating an implicit unconditional generator alongside the conditional ones [20, 11, 11].
We propose Contrastive Flow Matching (FM), a new approach that augments the flow matching objective with an auxiliary contrastive learning objective. FM encourages more diverse and distinct conditional generations. It applies a contrastive loss on the flow vectors (or representations) of samples within each training batch, encouraging the model to produce dissimilar flows for different conditioning inputs. Intuitively, this loss penalizes the model if two samples with different conditions yield similar flow dynamics, thereby explicitly discouraging the collapse of multiple conditions onto a single “average” generative trajectory. As a result, given a particular condition, the model learns to generate a unique flow through latent space that is characteristic of that condition alone, leading to more varied and condition-specific outputs. Importantly, this contrastive augmentation is complementary to existing methods. It can be applied along with REPA, further ensuring that flows not only align with pretrained features but also remain distinct across conditions. Likewise, it is compatible with classifier-free guidance at sampling time, allowing one to combine its benefits with CFG for even stronger conditional signal amplification.
Inspired by contrastive training objectives, FM applies a pairwise loss term between samples in a training batch: for each positive sample from the batch, we randomly sample a negative counterpart. We then encourage the model to not only learn the flow towards the positive sample but also to learn the flow away from the negative sample. This is achieved by adding a contrastive loss to the flow matching objective, which promotes class separability throughout the flow. Our method is simple to implement and can be easily integrated into existing diffusion models without any additional data and with minimal computational overhead.
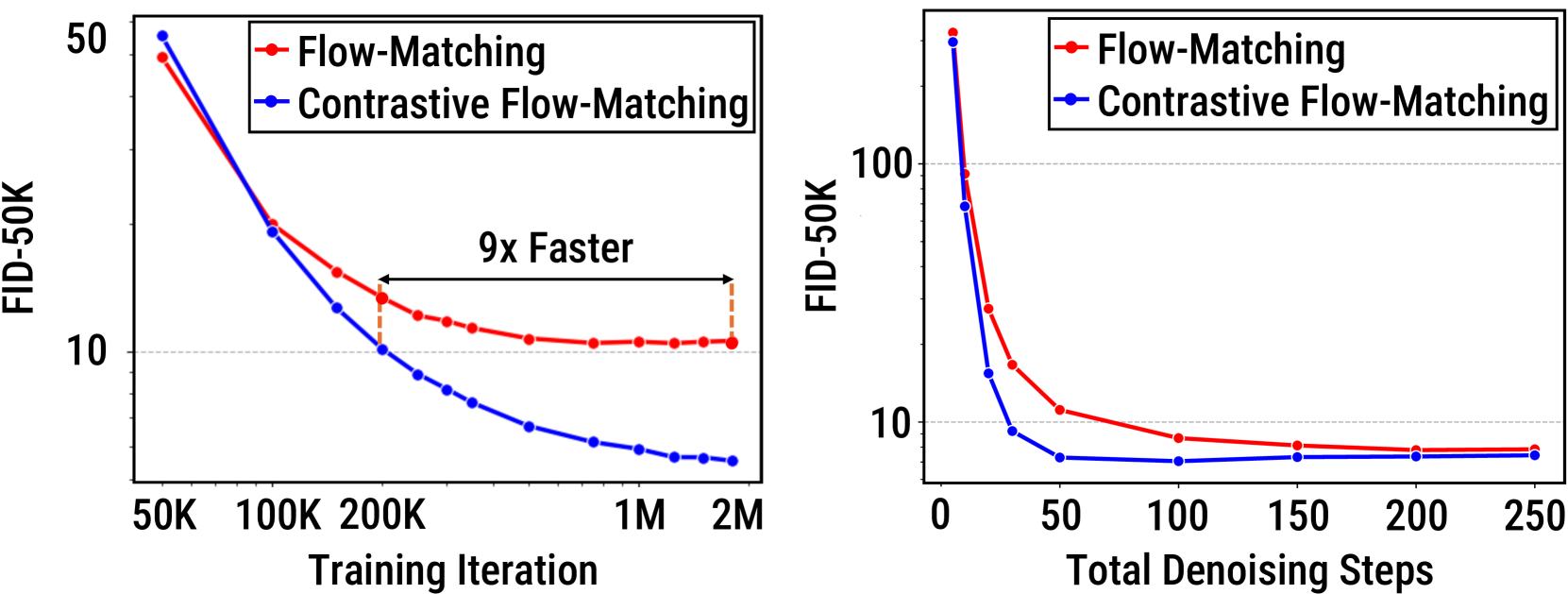
We validate the advantages of FM through (1) extensive experiments on conditional image generation using ImageNet images across multiple SiT [29] model scales and training frameworks [29, 44], and (2) text-to-image experiments on the CC3M [37] with the MMDiT [14] architecture. Thanks to contrastive flows, FM consistently outperforms traditional diffusion flow matching in quality and diversity metrics, achieving up to an -point reduction in FID-50K on ImageNet, and -point reduction in FID on the whole CC3M validation set. It is also compatible with recent significant improvements in the diffusion objective, such as Representation Alignment (REPA) [44]. By encouraging class separability, FM is able to efficiently reach a given image quality with fewer sampling steps than a baseline Flow Matching model, translating directly to faster generation. It also enhances training efficiency by up to 9. Finally, FM stacks with classifier-free guidance, lowering FID by 5.7% compared to flow matching models.
2 Related works
Our work lies in the domain of image generative models, primarily diffusion and flow matching models. We augment flow-matching with a contrastive learning objective to provide an alternative solution to classifier free guidance.
Generative modeling has rapidly advanced through two primary paradigms: diffusion-based methods [19, 39] and flow matching [25]. Denoising diffusion models typically rely on stochastic differential equations (SDEs) and score-based learning to iteratively add and remove noise [19]. Denoising diffusion implicit models (DDIMs) [39] reduce this sampling complexity by removing non-determinism in the reverse process, while progressive distillation [34] further accelerates inference by shortening the denoising chain. Advanced ODE solvers [6] and distillation methods [41] have also enhanced sampling efficiency. Despite their success, diffusion models can be slow at inference due to iterative denoising [19].
Flow matching [6] has been designed to reduce inference steps. It directly parameterizes continuous-time transport dynamics for more efficient sampling. Probability flow ODEs [39, 25] learn an explicit transport map between data and latent distributions. Unlike diffusion models, it bypasses separate score estimation and stochastic noise, which reduces function evaluations and tends to improve training convergence [6]. A common type of flow matching algorithm popularized recently is the rectified flow [26], which refines probability flow ODEs through direct optimal transport learning, improving numerical stability and sampling speed. This approach mitigates the high computational burden of diffusion sampling while maintaining high-fidelity image generation with fewer integration steps.
Since both diffusion and flow matching models are trained to match the target distribution of real images, they often produce ‘averaged’ samples that lack the sharp details and strong conditional fidelity [17]. Regardless of how much these models speed up, they often need to be invoked multiple times with unique seed noise to find a high-fidelity sample. In response, guidance techniques have been introduced to substantially promote high-fidelity synthesis. Classifier guidance [12], classifier-free guidance [17], energy guidance [8, 45, 27, 40], and more advanced methods [23, 20, 9, 21, 38] improve fidelity and controllability, without requiring multiple invocations. Although they achieve remarkable performance, they typically still require additional computational overhead. CFG requires calling sampling from a second ‘unconditional’ generation and guiding the ‘conditional’ generation away from the unconditional variant [28, 43, 42, 46]. We adapt the flow matching objective with a contrastive loss between the transport vectors within a batch. By doing so, we achieve the same benefits of CFG, without the additional overhead of needing to train an unconditional generator or using one during inference.
Contrastive learning was originally proposed for face recognition [36], where it was designed to encourage a margin between positive and negative face pairs. In generative adversarial networks (GANs), it has been applied to improve sample quality by structuring latent representations [4]. However, to the best of our knowledge, it has not been explored in the context of visual diffusion or flow matching models. We incorporate this contrastive objective to demonstrate its utility in speeding up training and inference of flow-based generative models.
3 Background and motivation
We focus on flow matching models [25] due to its rising popularity as an effective training paradigm for generative models [24, 1, 2]. In this section, we provide a brief overview of flow matching through the perspective of stochastic interpolants [2, 29], as it pertains to our work.
Preliminaries.
Let be an arbitrary distribution defined on the reals, and let be a Gaussian noise distribution. The objective of flow matching is to learn a transport between the two distributions. That is, given an arbitrary , a flow matching model gradually transforms over time into an that is part of . Stochastic interpolants [2, 29] define this transformation as a time-dependent stochastic process, where transformation steps are summarized as follows,
| (1) |
where and are decreasing and increasing time-dependent functions respectively defined on , such that and . While theoretically, need not be linear, linear complexity is often sufficient to obtain strong diffusion models [29, 25, 44].
Flow matching.
Given such a process, flow matching models learn to transport between noise to by estimating a velocity field over an probability flow ordinary differential equation (PF ODE), , whose distribution at time is the marginal . This velocity is given by the expectations of and conditioned on ,
| (2) |
where are the time-based derivatives of and respectively. Since, and are arbitrary samples from their respective distributions, is expected “direction” of all transport paths between noise and that pass through at . While the optimal is intractable, it can be approximated with a flow-model , by minimizing the training objective:
| (3) |
Key to understanding the properties of flow matching is the concept of flow uniqueness [25]. That is, flows following the well-defined ODE cannot intersect at any time . As such, flow models can iteratively refine unique-discriminative features relevant to any in each , leading to more efficient and accurate diffusion paths compared to other training paradigms [25].
Conditional flow matching.
Commonly, may be a marginal distribution over several class-conditional distributions (e.g., the classes of ImageNet [33]). Training models in such cases is nearly identical to standard flow-matching, except that flows are further conditioned on the target distribution class:
| (4) |
where . Resultant models have the desirable trait of being more controllable: their generated outputs can be tailored to their respective input conditions. However, this comes at the notable cost of flow-uniqueness. Specifically these models only generate unique flows compared to others within the same class-condition, not necessarily across classes. This inhibits ’s from storing important class-specific features and leads to poorer quality generations. Second, the conditional flow matching objective trains models without knowledge of the distributional spread from other class-conditions, leading to flows that may generate ambiguous outputs when conditional distributions overlap . This increases the likelihood of ambiguous generations that form a mixture between different conditions, restricting model capabilities. We study these effects in Section 5.
4 Contrastive Flow-Matching
We introduce Contrastive Flow Matching (FM), a novel approach designed to address the challenges of learning efficient class-distinct flow representations in conditional generative models. Standard conditional flow matching (FM) models tend to produce flow trajectories that align across different samples, leading to reduced class separability. FM extends the FM objective by incorporating a contrastive regularization term, which explicitly discourages alignment between the learned flow trajectories of distinct samples.
Ingredients.
Let denote a sample drawn from the data distribution conditioned on an arbitrary class , and let represent an independent noise sample. To ensure that the contrastive objective captures distinct flow trajectories, we impose the conditions and , where may or may not be equal to . Importantly, we do not assume the existence of a time step such that . Consequently, and represent truly independent flow trajectories in comparison to and .
The contrastive regularization.
Given and an arbitrary sample pair, the contrastive objective aims to maximize the dissimilarity between the estimated flow of from to , and the independent flow produced by . We achieve this by maximizing the quantity,
| (5) |
Since is drawn from the marginal rather than , Equation 5 trains flow matching models to produce flows that are unconditionally unique.
Putting it all together.
We now define contrastive flow matching as follows,
| (6) |
where is a fixed hyperparameter that controls the strength of the contrastive regularization. Thus, FM simultaneously encourages flow matching models to estimate effective transports from noise to corresponding class-conditional distributions (the flow matching objective), while enforcing each to be discriminative across classes (contrastive regularization). Note that FM can be thought of as a generalization of flow matching, as FM reduces to FM when . We study the effects of varying in Section 5.5.
Implementation.
Contrastive flow matching (FM) is easily integrated into any flow matching training loop, with minimal overhead. Algorithm 1 illustrates the implementation of an arbitrary batch step, where navy text marks additions to the standard flow matching objective. Thus, FM solely depends on the information already available to the flow matching objective at each batch step, without computing any additional forward steps. Furthermore, FM seamlessly folds into flow matching training regimes, making it a “plug-and-play” objective for existing setups.
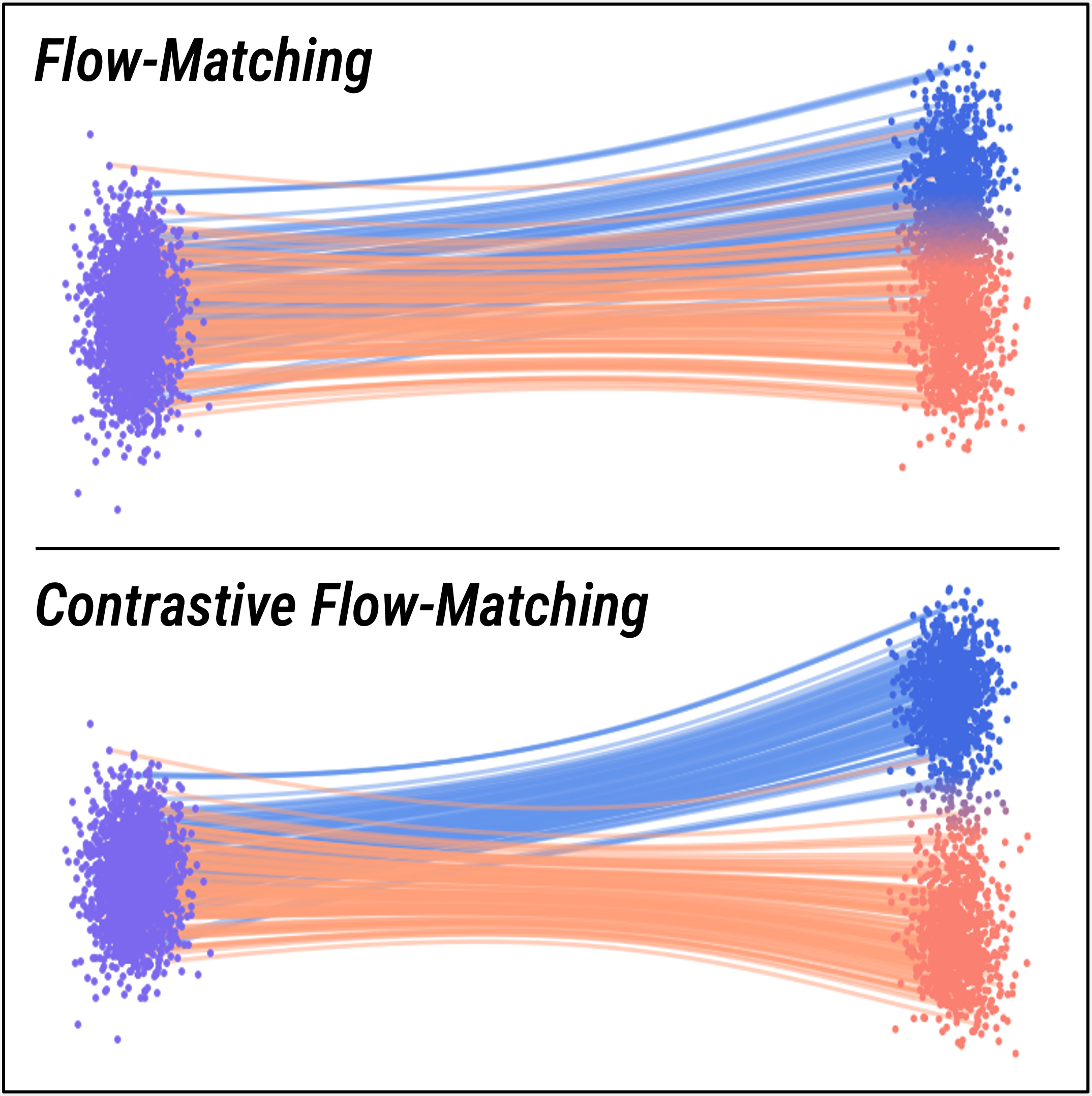
Discussion.
Figure 3 illustrates the effects of contrastive flow matching compared to flow matching. The figure shows the resultant flows after training a small diffusion model in a simple toy-setting. Specifically, we create a two-dimensional violet gaussian noise distribution and two independent two-dimensional class distributions (in blue and orange respectively) such that the latter distributions have overlap. Samples from each distribution are represented as “dots”, with those in the target distributions colored according to the gaussian kernel-density estimate between samples from each class in their respective region. We observe that training the model with flow matching (top) create flows with large degrees of overlap between classes, generating samples with lower class-distinction. In contrast, training the same model with contrastive flow matching (bottom) yields trajectories that are significantly more diverse across classes, while also generating samples which capture distinct features of each respective class.
5 Experiments
We validate contrastive flow-matching (FM) through extensive experiments across various model, training and benchmark configurations. Overall, models trained with FM consistently outperform flow-matching (FM) models across all settings.
Datasets.
We conduct both class-conditioned and text-to-image experiments. We use ImageNet-1k [10] processed at both () and () resolutions for our class-conditioned experiments, and follow the data preprocessing procedure of ADM [12] We then follow [44] and encode each image using the Stable Diffusion VAE [32] into a tensor . For text-to-image (t2i), we use the Conceptual Captions 3M (CC3M) dataset [37] processed at () resolution and follow the data processing procedure of [3]. We train all models by strictly following the setup in [44], and use a batch size of 256 unless otherwise specified. We do not alter the training conditions to be favorable to FM, and we always set when applicable.
Measurements.
We report five quantitative metrics throughout our experiments. We report Fréchet inception distance (FID) [16], inception score (IS) [35], sFID [30], precision (Prec.) and recall (Rec.) [22] using 50,000 samples for our class-conditioned experiments. Similarly, we report FID over the whole validation set in the text-to-image setting. We use the SDE Euler-Maruyama sampler with for all experiments, and set the number of function evaluations (NFE) to 50 unless otherwise specified.
5.1 Contrastive Flow-Matching Improves SiT
Implementation details.
We train on the state-of-the-art SiT [29] model architecture, using both SiT-B/2 and SiT-XL/2.
| Metrics | |||||
|---|---|---|---|---|---|
| Model | FID | IS | sFID | Prec. | Rec. |
| SiT-B/2 | 42.28 | 38.04 | 11.35 | 0.5 | 0.62 |
| + Using FM | 33.39 | 43.44 | 5.67 | 0.53 | 0.63 |
| SiT-XL/2 | 20.01 | 74.15 | 8.45 | 0.63 | 0.63 |
| + Using FM | 16.32 | 78.07 | 5.08 | 0.66 | 0.63 |
| Metrics | |||||
|---|---|---|---|---|---|
| Model | FID | IS | sFID | Prec. | Rec. |
| SiT-B/2 | 50.26 | 33.58 | 14.88 | 0.57 | 0.61 |
| + Using FM | 41.59 | 38.20 | 6.13 | 0.62 | 0.63 |
| SiT-XL/2 | 22.98 | 70.14 | 10.71 | 0.73 | 0.60 |
| + Using FM | 19.67 | 72.58 | 4.98 | 0.76 | 0.60 |
Results.
Table 1 summarizes our results. Overall, FM dramatically improves over flow-matching in nearly all metrics (only matching the flow-matching SiT-XL/2 model in recall). Notably, employing FM with SiT-B/2 lowers FID by over 8 compared to flow-matching at both ImageNet resolutions, highlighting the strength of FM in smaller model scales. Similarly, FM is robust to larger model scales and outperforms FM by over 3.2 FID when using SiT-XL/2.
5.2 REPA is complementary
REPresentation Alignment (REPA) [44] is a recently introduced training framework that rapidly improves diffusion model performance by strengthening its intermediate representations. Specifically, REPA distills the encodings of foundation vision encoders (e.g., DiNOv2 [5]) into the hidden states of diffusion models through the use of an auxilliary objective. Notably, REPA can improve the training speed of vanilla SiT models by over , while further improving their performances [44]. FM is easily integrated into REPA and only requires replacing the flow-matching objective.
Implementation details.
We apply REPA on the same SiT models as in Section 5.1, and use the distillation process defined by [44] exactly. Specifically, we use distill DiNOv2 [5] ViT-B [13] features into the 4th layer of the SiT-B/2, and the 8th layer of the SiT-XL/2, and mirror their hyperparameter setup.
| Metrics | |||||
|---|---|---|---|---|---|
| Model | FID | IS | sFID | Prec. | Rec. |
| REPA SiT-B/2 | 27.33 | 61.60 | 11.70 | 0.57 | 0.64 |
| + Using FM | 20.52 | 69.71 | 5.47 | 0.61 | 0.63 |
| REPA SiT-XL/2 | 11.14 | 115.83 | 8.25 | 0.67 | 0.65 |
| + Using FM | 7.29 | 129.89 | 4.93 | 0.71 | 0.64 |
| Metrics | |||||
|---|---|---|---|---|---|
| Model | FID | IS | sFID | Prec. | Rec. |
| REPA SiT-B/2 | 31.90 | 56.96 | 13.78 | 0.67 | 0.62 |
| + Using FM | 24.48 | 64.74 | 5.89 | 0.71 | 0.61 |
| REPA SiT-XL/2 | 11.32 | 119.72 | 10.21 | 0.76 | 0.63 |
| + Using FM | 7.64 | 131.50 | 4.72 | 0.79 | 0.62 |
Results.
We report results in Table 2. Similar to Section 5.1, FM substantially improves REPA models by as much as 6.81 FID, and consistently improves flow-matching with model scale. This highlights the versatility of the contrastive flow-matching objective as a broadly applicable criterion for diffusion model.

5.3 Extending to text-to-image generation
Implementation Details.
We train models with the popular MMDiT [14] architecture from scratch on the CC3M dataset [37] for 400K iterations. For faster training, we pair each model with REPA, and follow the recommended training protocol of [44].
| Metric | REPA-MMDiT | |
|---|---|---|
| Flow-Matching | FM | |
| FID | 24 | 19 |
Results.
5.4 CFG stacks with contrastive flow matching
Contrastive flow matching offers advantages of Classifier-Free Guidance (CFG), without incurring additional computational costs during inference. In this section, we demonstrate that when computational resources permit, combining FM with CFG can yield further performance enhancements.
Accounting for conflicts.
CFG and FM encourage flow matching model generations to be unique and identifiable, in different ways. Specifically, FM trains models whose conditional flows are steered away from other arbitrary flows in the training data, regardless of generation state (). In contrast, CFG steers generations away from the unconditional flow estimates based on . Thus, the signals from each may not always be aligned and naively coupling them may lead to conflicts and suboptimal generations. Fortunately, we can quantify the amount of steerage FM applies on flow matching models by deriving the closed-form solution to Eq. 4: , where is simply the mean of all sample trajectories from the training set (please see App. B.1 for the full derivation). Thus, FM yields models which estimate flows away from the data-driven unconditional trajectory, weighted by . While optimizer and training dynamics cannot guarantee that all models trained with FM exactly decompose into these terms, nevertheless approximates its effect on these models. With , we can account for conflicts between FM and CFG by modifying the CFG equation to: , where is the guidance scale, is the unconditional term and is the same parameter used during FM training (Appendix B.2 contains the full derivation). Note that, we only apply within the specified guidance interval , and use our unchanged FM model outside this interval.
| Model | CFG Terms | Metric | ||||
|---|---|---|---|---|---|---|
| IS | FID | sFID | ||||
| REPA SiT-XL/2 | 1.75 | 0.0 | 0.75 | 280.33 | 2.09 | 5.55 |
| + Using FM | 1.85 | 0.0 | 0.65 | 281.95 | 1.97 | 4.49 |
Results.
Table 4 summarizes the results. When paired with CFG, FM improves flow matching models across all metrics, demonstrating its efficacy in settings where computational costs are not a constraint.
Additional Couplings.
While we find that our proposed coupling strategy for FM and CFG works well for our setting, other suitable variations may also exist. For instance, one may instead reduce conflicts by following the equation: , where are free hyperparameters. We leave such exploration to future work.
5.5 Analyzing Contrastive Flow-Matching
Understanding the FM weight ().
directly controls how unique flows are across classes. Increasing encourages every diffusion step to be fully discriminative, enabling models to encode distinct representations that integral to generating strong visual outputs at each trajectory step. However, setting it too high can lead to overly-separated flow trajectories, making it difficult to capture the class structure (Table 5). However, values that are too low mirror the flow matching objective. Notably, we find that is stable across all model and dataset settings, consistently achieving strong performance.
| Metric | FM Values | |||||
|---|---|---|---|---|---|---|
| IS | 115.83 | 115.70 | 119.41 | 129.89 | 116.27 | 82.20 |
| FID | 11.14 | 10.93 | 9.93 | 7.29 | 9.86 | 19.21 |
Earlier class differentiation during denoising. In Figure 4, we study flow trajectories of standard flow matching (FM) and flow matching with FM. To do this, we take partially denoised latents at various intermediate time steps along a trajectory with total length 30. While initially both follow similar trajectories, they quickly diverge within the first several steps of the denoising process. For instance, the model trained with FM produces more structurally coherent images earlier (around 15 to 20 steps in) than with FM. The iconic features of each class, such as slanted bridge surfaces (Figure 4 (top-left)), animal eyes (Figure 4 (upper-left and top-right), and train windows (Figure 4 (upper-right)), are more clearly visible early on during the diffusion process of the FM model. This enables FM to ultimately generate higher quality images at the final timestep.
| Metrics | ||||
|---|---|---|---|---|
| Model | Batch Size | FID | IS | sFID |
| REPA SiT-B/2 | 256 | 42.28 | 38.04 | 11.35 |
| + Using FM | 256 | 33.39 | 43.44 | 5.67 |
| REPA SiT-B/2 | 512 | 24.45 | 69.15 | 11.42 |
| + Using FM | 512 | 17.06 | 81.41 | 5.29 |
| REPA SiT-B/2 | 1024 | 22.00 | 76.15 | 11.76 |
| + Using FM | 1024 | 15.23 | 88.53 | 5.20 |
| REPA SiT-XL/2 | 256 | 11.14 | 115.83 | 8.25 |
| + Using FM | 256 | 7.29 | 129.89 | 4.93 |
| REPA SiT-XL/2 | 512 | 10.15 | 129.43 | 9.00 |
| + Using FM | 512 | 6.36 | 146.17 | 5.42 |
Effects of batch size on FM. In Table 6, we study the effects of batch size on our loss. It is well known that batch size has an important effect on contrastive style losses [5, 7, 15] that draw negatives within the batch. This can be understood as a sample diversity issue. If the batch size is larger than negative samples within the batch are more representative of the true distribution. In this table, we see a similar trend: larger batch sizes are important for maximizing the performance of FM across several model scales. We also maintain our improvements over the REPA baseline through all batch sizes and model scales.
Improved training and inference speed. In Figure 5 (left), we see the significant improvements in training speed from the FM objective. We reach the same performance (measured by FID-50k) as baseline with fewer training iterations. In Figure 5 (right), we also demonstrate significant improvements at inference time. With our objective, we reach superior performance with only 50 denoising steps compared to the baseline with 250 denoising steps. This is a linear 5 improvement in training efficiency. Taken together, these results emphasize the important gains in computational efficiency achieved by our method.
6 Conclusion
We introduced Contrastive Flow Matching (FM), a simple addition to the diffusion objective that enforces distinct, diverse flows during image generation. Quantitatively, FM results in improved image quality with far fewer denoising steps ( faster) and significantly improved training speed ( faster). Qualitatively, FM improves the structural coherence and global semantics for image generation. All of this is achieved with negligible extra compute per training iteration. Finally, we show that our improvements stack with the recently proposed Representation Alignment (REPA) loss, allowing for strong gains in image generation performance. Looking forward, FM shows the possibility that deviating from perfect distribution modeling in the diffusion objective might result in better image generation.
References
- Albergo and Vanden-Eijnden [2022] Michael S Albergo and Eric Vanden-Eijnden. Building normalizing flows with stochastic interpolants. arXiv preprint arXiv:2209.15571, 2022.
- Albergo et al. [2023] Michael S Albergo, Nicholas M Boffi, and Eric Vanden-Eijnden. Stochastic interpolants: A unifying framework for flows and diffusions. arXiv preprint arXiv:2303.08797, 2023.
- Bao et al. [2023] Fan Bao, Shen Nie, Kaiwen Xue, Yue Cao, Chongxuan Li, Hang Su, and Jun Zhu. All are worth words: A vit backbone for diffusion models. In CVPR, 2023.
- Cao et al. [2017] Gongze Cao, Yezhou Yang, Jie Lei, Cheng Jin, Yang Liu, and Mingli Song. Tripletgan: Training generative model with triplet loss, 2017.
- Caron et al. [2021] Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. In ICCV, 2021.
- Chen et al. [2018] Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David Duvenaud. Neural ordinary differential equations. In Advances in Neural Information Processing Systems, 2018.
- Chen et al. [2020] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. ICLR, 2020.
- Chung et al. [2022] Hyungjin Chung, Jeongsol Kim, Michael T Mccann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. arXiv preprint arXiv:2209.14687, 2022.
- Chung et al. [2024] Hyungjin Chung, Jeongsol Kim, Geon Yeong Park, Hyelin Nam, and Jong Chul Ye. Cfg++: Manifold-constrained classifier free guidance for diffusion models. arXiv preprint arXiv:2406.08070, 2024.
- Deng et al. [2009] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee, 2009.
- Desai and Vasconcelos [2024] Alakh Desai and Nuno Vasconcelos. Improving image synthesis with diffusion-negative sampling, 2024.
- Dhariwal and Nichol [2021] Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis. Advances in neural information processing systems, 34:8780–8794, 2021.
- Dosovitskiy et al. [2021] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
- Esser et al. [2024] Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, Dustin Podell, Tim Dockhorn, Zion English, and Robin Rombach. Scaling rectified flow transformers for high-resolution image synthesis. ICML, 2024.
- He et al. [2020] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. CVPR, 2020.
- Heusel et al. [2017] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems, 30, 2017.
- Ho and Salimans [2022a] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598, 2022a.
- Ho and Salimans [2022b] Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance, 2022b.
- Ho et al. [2020] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In Advances in Neural Information Processing Systems, 2020.
- Karras et al. [2024] Tero Karras, Miika Aittala, Tuomas Kynkäänniemi, Jaakko Lehtinen, Timo Aila, and Samuli Laine. Guiding a diffusion model with a bad version of itself. arXiv preprint arXiv:2406.02507, 2024.
- [21] Felix Koulischer, Johannes Deleu, Gabriel Raya, Thomas Demeester, and Luca Ambrogioni. Dynamic negative guidance of diffusion models: Towards immediate content removal. In Neurips Safe Generative AI Workshop 2024.
- Kynkäänniemi et al. [2019] Tuomas Kynkäänniemi, Tero Karras, Samuli Laine, Jaakko Lehtinen, and Timo Aila. Improved precision and recall metric for assessing generative models. NeurIPS, 2019.
- Kynkäänniemi et al. [2024] Tuomas Kynkäänniemi, Miika Aittala, Tero Karras, Samuli Laine, Timo Aila, and Jaakko Lehtinen. Applying guidance in a limited interval improves sample and distribution quality in diffusion models. arXiv preprint arXiv:2404.07724, 2024.
- Lipman et al. [2023a] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. In ICLR, 2023a.
- Lipman et al. [2023b] Yaron Lipman, Ricky T. Q. Chen, Heli Ben-Hamu, Maximilian Nickel, and Matthew Le. Flow matching for generative modeling. In ICLR, 2023b.
- Liu et al. [2022] Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow, 2022.
- Lu et al. [2023] Cheng Lu, Huayu Chen, Jianfei Chen, Hang Su, Chongxuan Li, and Jun Zhu. Contrastive energy prediction for exact energy-guided diffusion sampling in offline reinforcement learning. In International Conference on Machine Learning, pages 22825–22855. PMLR, 2023.
- Luo et al. [2023] Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference. arXiv preprint arXiv:2310.04378, 2023.
- Ma et al. [2024] Nanye Ma, Mark Goldstein, Michael S. Albergo, Nicholas M. Boffi, Eric Vanden-Eijnden, and Saining Xie. Sit: Exploring flow and diffusion-based generative models with scalable interpolant transformers. 2024.
- Nash et al. [2021] Charlie Nash, Jacob Menick, Sander Dieleman, and Peter W Battaglia. Generating images with sparse representations. arXiv preprint arXiv:2103.03841, 2021.
- Oquab et al. [2024] Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V. Vo, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel HAZIZA, Francisco Massa, Alaaeldin El-Nouby, Mido Assran, Nicolas Ballas, Wojciech Galuba, Russell Howes, Po-Yao Huang, Shang-Wen Li, Ishan Misra, Michael Rabbat, Vasu Sharma, Gabriel Synnaeve, Hu Xu, Herve Jegou, Julien Mairal, Patrick Labatut, Armand Joulin, and Piotr Bojanowski. DINOv2: Learning robust visual features without supervision. TMLR, 2024.
- Rombach et al. [2022] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022.
- Russakovsky et al. [2015] Olga Russakovsky, Jia Deng, Hao Su, Jonathan Krause, Sanjeev Satheesh, Sean Ma, Zhiheng Huang, Andrej Karpathy, Aditya Khosla, Michael Bernstein, Alexander C. Berg, and Li Fei-Fei. Imagenet large scale visual recognition challenge, 2015.
- Salimans and Ho [2022] Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022.
- Salimans et al. [2016] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans. Advances in neural information processing systems, 29, 2016.
- Schroff et al. [2015] Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), page 815–823. IEEE, 2015.
- Sharma et al. [2018] Piyush Sharma, Nan Ding, Sebastian Goodman, and Radu Soricut. Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In Proceedings of ACL, 2018.
- Shenoy et al. [2024] Rahul Shenoy, Zhihong Pan, Kaushik Balakrishnan, Qisen Cheng, Yongmoon Jeon, Heejune Yang, and Jaewon Kim. Gradient-free classifier guidance for diffusion model sampling. arXiv preprint arXiv:2411.15393, 2024.
- Song et al. [2021] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models. In International Conference on Learning Representations, 2021.
- Song et al. [2023] Jiaming Song, Qinsheng Zhang, Hongxu Yin, Morteza Mardani, Ming-Yu Liu, Jan Kautz, Yongxin Chen, and Arash Vahdat. Loss-guided diffusion models for plug-and-play controllable generation. In International Conference on Machine Learning, pages 32483–32498. PMLR, 2023.
- Vahdat et al. [2021] Arash Vahdat, Karsten Kreis, and Jan Kautz. Score-based generative modeling in latent space, 2021.
- Yin et al. [2024a] Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. arXiv preprint arXiv:2405.14867, 2024a.
- Yin et al. [2024b] Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6613–6623, 2024b.
- Yu et al. [2024] Sihyun Yu, Sangkyung Kwak, Huiwon Jang, Jongheon Jeong, Jonathan Huang, Jinwoo Shin, and Saining Xie. Representation alignment for generation: Training diffusion transformers is easier than you think, 2024.
- Zhao et al. [2022] Min Zhao, Fan Bao, Chongxuan Li, and Jun Zhu. Egsde: Unpaired image-to-image translation via energy-guided stochastic differential equations. Advances in Neural Information Processing Systems, 35:3609–3623, 2022.
- Zhou et al. [2024] Mingyuan Zhou, Zhendong Wang, Huangjie Zheng, and Hai Huang. Long and short guidance in score identity distillation for one-step text-to-image generation. arXiv preprint arXiv:2406.01561, 2024.

Appendix A Text-to-Image Qualitative Results
We visualize generations between our REPA-MMDiT models described in Section 5.3 trained with flow-matching (FM) loss and with FM on CC3M with a batch size of 256 for 400K iterations in Figure 6. We plot images in pairs, with FM images on the left and FM images on the right, and show the respective caption for each pair above. All images are generated without classifier-free guidance and using NFE=50, and are the same images used in Table 3.
Appendix B Deriving Contrastive-Flow Matching Interference
B.1 Closed-form solution to Eq. 4
We first re-introduce Eq. 4 for convenience,
Minimizing the expectation, expanding all norms and letting , we can simplify the expectation to:
| (7) | ||||
| (8) | ||||
| (9) | ||||
Setting the gradient with respect to to ,
| (10) | ||||
| (11) |
Finally, observe that is the solution to the flow-matching objective. Setting and observing that does not depend on or we obtain:
| (12) |